Blocks and batches
Overview of blocks and batches
ZKsync Chains process transactions not only as individual units but also groups them into blocks and batches for efficiency and cost-effectiveness. This section covers how transactions are grouped, the concept of sealing blocks, and why rollbacks are crucial in our virtual machine (VM).
Understanding L2 and L1 blocks
L2 blocks, also referred to as miniblocks, are specific to ZKsync Chains and are not recorded on the Ethereum blockchain. These blocks contain a smaller number of transactions, allowing for quick processing.
Contrastingly, L1 rollup blocks, or batches, consist of several consecutive L2 blocks. These batches compile all transactions from multiple L2 blocks in the same sequence they were processed. The primary purpose of creating batches is to minimize the costs associated with Ethereum interactions by distributing them across numerous transactions.
Differences between batch, block, and transaction
To clarify these concepts visually, consider the following illustrations:
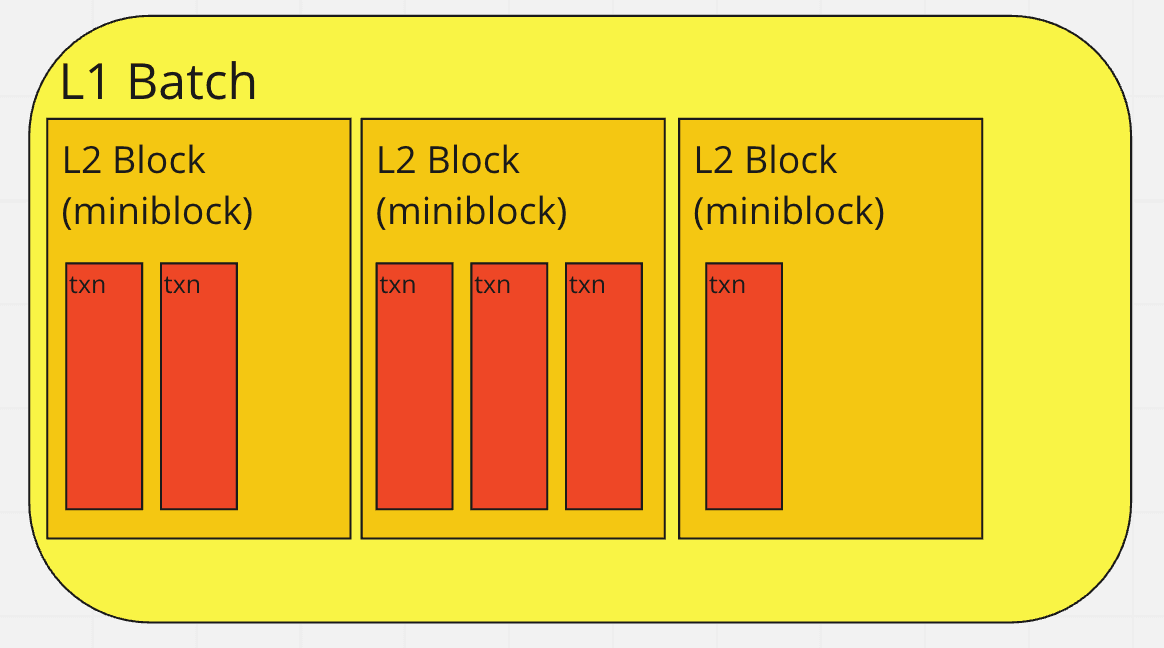 The Block layout image displays the organization of transactions within blocks and how L2 blocks are arranged within L1 batches.
The Block layout image displays the organization of transactions within blocks and how L2 blocks are arranged within L1 batches.
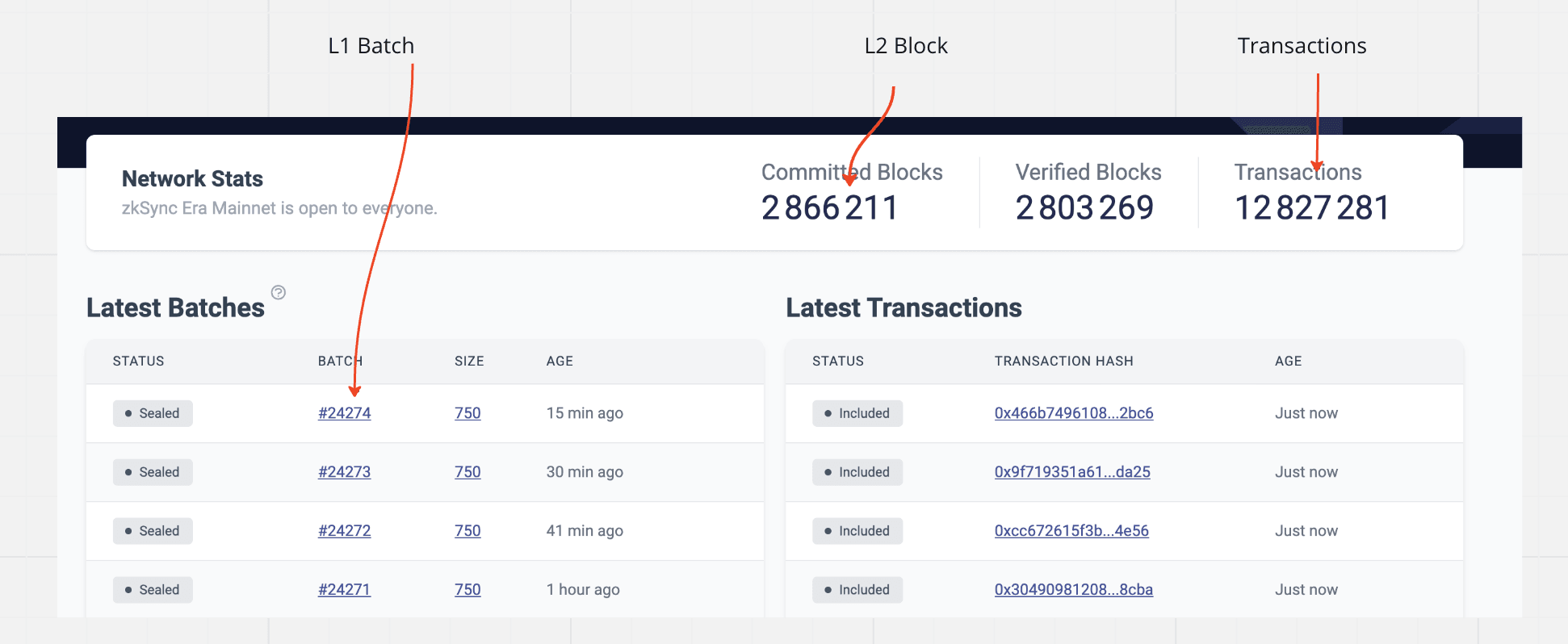 This Explorer example shows how the ZKsync Era explorer represents blocks and transactions.
This Explorer example shows how the ZKsync Era explorer represents blocks and transactions.
Detailed look at L2 blocks
While L2 blocks are crucial, their importance will increase with the transition to a decentralized sequencer. Currently, they serve mainly as a compatibility feature for tools like Metamask, which expect frequent block updates to confirm transaction statuses.
An L2 block is generated every 1 second, encompassing all transactions received within that timeframe. This rapid creation ensures consistent transaction processing.
(You can check the difference between RemainingBlock and EstimateTimeInSec from
the block countdown api endpoint),
and it includes all the transactions received during that time period.
This periodic creation of L2 blocks ensures that transactions are processed and included in the blocks regularly.
Properties of L2 blocks
The properties of an L2 block can be observed when using the getBlock method from our SDKs:
| Parameter | Description |
|---|---|
| hash | The hash of the L2 block, null if pending |
| parentHash | Refers to the hash of the parent block in L2 |
| number | The current L2 block number, null if pending |
| timestamp | UNIX timestamp for when the L2 block was formed |
| nonce | Tracks the most recent transaction by the account's counter |
| difficulty | Always returns 2500000000000000 as ZKsync does not use a proof of work consensus |
| gasLimit | Maximum gas allowed in this block, always returns 2^32-1 |
| gasUsed | Actual amount of gas used in this block |
| transactions | An array of transaction objects - see TransactionResponse interface |
| baseFeePerGas | The base fee per gas in the style of EIP1559 |
The role of L1 batches
L1 batches are integral to ZKsync Chains as they represent the unit of computation for generating proofs. From a VM perspective, each L1 batch is akin to executing a program—the Bootloader, which processes all transactions within the batch.
L1 batch size and processing times
The sealing of a batch depends on several criteria, managed by the conditional_sealer module, including transaction count, size limits, gas limits, and more. The decision-making process is complex, often requiring a "try and rollback" approach for transactions that exceed the batch's capacity.
The conditional_sealer maintains a list of SealCriterion which include:
- Transaction count limit (that is, how many transactions would fit within a batch).
- Transaction size limit (that is, the total data/information within the transactions).
- L2 Gas limit.
- Published data limit (as each L1 batch must publish information about the changed slots to L1, so all the changes must fit within the L1 transaction limit).
- L1 Gas limit (Similar to the above, but ensuring the commit, prove and execute transactions on L1 wouldn't consume more gas than available).
- Circuits Geometry limits - For certain operations like merkle transformation, there is a maximum number of circuits that can be included in a single L1 batch. If this limit is exceeded, we wouldn't be able to generate the proof.
- Timeout (unlikely to ever be used, but ensures if there are not enough transactions to seal based on the other criteria, the batch is still sealed so information is sent to L1).
However, these sealing criteria pose a significant challenge because it is difficult to predict in advance whether adding a given transaction to the current batch will exceed the limits or not. This unpredictability adds complexity to the process of determining when to seal the block.
ExcludeAndSeal
To handle situations where a transaction exceeds the limits of the currently active L1 batch,
we employ a "try and rollback" approach.
This means that we attempt to add the transaction to the active L1 batch,
and if we receive a ExcludeAndSeal response indicating that it doesn't fit,
we roll back the virtual machine (VM) to the state before the transaction was attempted.
Implementing this approach introduces a significant amount of complexity in the oracles (also known as interfaces) of the VM.
These oracles need to support snapshotting and rolling back operations to ensure consistency when handling transactions that don't fit.
Retrieving block and batch numbers
Accessing block and batch numbers in ZKsync Chains is straightforward:
eth_blockNumberretrieves the latest L2 block number.eth_getBlockByNumberprovides details for a specific L2 block.zks_L1BatchNumberfetches the most recent batch number, critical for understanding the scope of transactions and operations within a ZKsync Chain.
Deeper dive into ZKsync's batch and block mechanisms
This section delves into the intricate processes involved in initializing and managing L1 batches and L2 blocks within ZKsync, providing insights into the technical frameworks and operational protocols.
Initializing L1 batch
At the start of each L1 batch, the operator submits essential data such as the batch's timestamp, its sequential number, and the hash of the previous batch. The Merkle tree's root hash serves as the foundational root hash for the batch. The SystemContext verifies these details immediately, ensuring consistency and integrity right from the initiation phase. The underlying operations and consistency checks are detailed here.
Processing and consistency checks of L2 blocks
setL2Block
Before processing each transaction,
the setL2Block method
is invoked, configuring the necessary parameters for the L2 block that will contain the transaction.
There we will provide some data about the L2 block that the transaction belongs to:
_l2BlockNumberThe number of the new L2 block._l2BlockTimestampThe timestamp of the new L2 block._expectedPrevL2BlockHashThe expected hash of the previous L2 block._isFirstInBatchWhether this method is called for the first time in the batch._maxVirtualBlocksToCreateThe maximum number of virtual block to create with this L2 block.
If two transactions belong to the same L2 block, only the first one may have non-zero _maxVirtualBlocksToCreate. The
rest of the data must be same.
Detailed operations can be found here.
L2 blockhash calculation and storage
The hash for each L2 block is dynamically calculated using keccak256, encoding various block details and transaction hashes.
This mechanism ensures that each block can be independently verified and traced within the L2 framework.
The hash of an L2 block is
keccak256(abi.encode(_blockNumber, _blockTimestamp, _prevL2BlockHash, _blockTxsRollingHash)).
_blockTxsRollingHash is defined in the following way:
_blockTxsRollingHash = 0 for an empty block.
_blockTxsRollingHash = keccak(0, tx1_hash) for a block with one tx.
_blockTxsRollingHash = keccak(keccak(0, tx1_hash), tx2_hash) for a block with two txs, etc.
To add a transaction hash to the current miniblock we use the appendTransactionToCurrentL2Blockfunction.
Since ZKsync is a state-diff based rollup, there is no way to deduce the hashes of the L2 blocks based on the transactions’ in the batch
(because there is no access to the transaction’s hashes).
At the same time, in order to serve blockhash method, the VM requires the knowledge of some of the previous L2 block hashes.
In order to save up on pubdata (by making sure that the same storage slots are reused, i.e. we only have repeated writes) we store only the
last 257 block hashes.
You can read more on what are the repeated writes and how the pubdata is processed on
Handling L1->L2 ops on ZKsync.
Legacy blockhash
For blocks that predate certain system upgrades (migration upgrades), the blockhash is generated using a simplified formula that incorporates only the block number. This method ensures backward compatibility and integrity across different block versions within the ZKsync system.
We use the following formula for their hash:
keccak256(abi.encodePacked(uint32(_blockNumber)))
Timing invariants
ZKsync Chains maintain strict timing invariants to ensure that each block's timestamp is accurate and consistent relative to other system timestamps.
These invariants include:
- For each L2 block its timestamp should be > the timestamp of the previous L2 block
- For each L2 block its timestamp should be ≥ timestamp of the batch it belongs to
- Each batch must start with a new L2 block (i.e. an L2 block can not span across batches).
- The timestamp of a batch must be ≥ the timestamp of the latest L2 block which belonged to the previous batch.
- The timestamp of the last miniblock in batch can not go too far into the future. This is enforced by publishing an L2→L1 log, with the timestamp which is then checked on L1.
Finalization of batches with fictive L2 blocks
At the end of each batch, a fictive L2 block is generated from the bootloader to finalize the transactions and prepare for the next batch. This block, typically empty, acts as a procedural step within the internal node operations. This empty block contains a Transfer event log, representing the bootloader transferring the collected fees to the operator. Additionally, the timestamps of the batch and the last miniblock are verified against realistic expectations on L1 to ensure temporal consistency and prevent future discrepancies.